> ## Documentation Index
> Fetch the complete documentation index at: https://portkey-docs-add-third-party-integration-issues-fixes.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Vercel AI SDK
> Use Portkey with Vercel AI SDK to build production-ready AI apps with full observability, reliability, and 250+ model support
Portkey seamlessly integrates with the Vercel AI SDK, enabling you to build production-ready AI applications with enterprise-grade reliability, observability, and governance. Simply point the OpenAI provider to Portkey's gateway and unlock powerful features:
* **Full-stack observability** - Complete tracing and analytics for every request
* **250+ LLMs** - Switch between OpenAI, Anthropic, Google, AWS Bedrock, and 250+ models
* **Enterprise reliability** - Fallbacks, load balancing, automatic retries, and circuit breakers
* **Smart caching** - Reduce costs up to 80% with semantic and simple caching
* **Production guardrails** - 50+ built-in checks for safety and quality
* **Prompt management** - Version, test, and deploy prompts from Portkey's studio
**Migrated from `@portkey-ai/vercel-provider`?**
We've updated our integration to use Vercel's standard OpenAI provider for better compatibility with the rapidly evolving Vercel AI SDK. This new approach gives you access to all Vercel features while maintaining full Portkey functionality.
## Quick Start
### 1. Installation
```sh theme={null}
npm install ai @ai-sdk/openai
```
### 2. Get Your Portkey API Key
[Sign up for Portkey](https://app.portkey.ai) and copy your API key from the dashboard. You'll use this to authenticate with Portkey's gateway.
### 3. Configure the OpenAI Provider
Point the OpenAI provider to Portkey's gateway:
```typescript theme={null}
import { createOpenAI } from '@ai-sdk/openai';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY', // Your Portkey API key
});
```
### 4. Use Any Model
Use models from your [AI Providers](/product/model-catalog) with the `@provider-slug/model-name` format:
```typescript theme={null}
import { generateText } from 'ai';
const { text } = await generateText({
model: openai('@openai-prod/gpt-4o'),
prompt: 'Write a vegetarian lasagna recipe for 4 people.',
});
console.log(text);
```
That's it! Your Vercel AI SDK app now has full Portkey observability and reliability features.
## Core Features
### Text Generation
Generate text with any model using `generateText`:
```typescript OpenAI Models theme={null}
import { generateText } from 'ai';
import { createOpenAI } from '@ai-sdk/openai';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
const { text } = await generateText({
model: openai('@openai-prod/gpt-4o'),
prompt: 'Write a haiku about coding.',
});
```
```typescript Anthropic Models theme={null}
import { generateText } from 'ai';
import { createOpenAI } from '@ai-sdk/openai';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
// Use .chat() for chat completion models
const { text } = await generateText({
model: openai.chat('@anthropic-prod/claude-3-5-sonnet-20240620'),
prompt: 'Explain quantum computing.',
});
```
```typescript Google Models theme={null}
import { generateText } from 'ai';
import { createOpenAI } from '@ai-sdk/openai';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
const { text } = await generateText({
model: openai.chat('@google-prod/gemini-2.0-flash'),
prompt: 'What are the benefits of solar energy?',
});
```
Use `openai()` for OpenAI's completion models and `openai.chat()` for chat completion models from any provider (Anthropic, Google, AWS Bedrock, etc.).
### Streaming Text
Stream responses in real-time with `streamText`:
```typescript theme={null}
import { streamText } from 'ai';
import { createOpenAI } from '@ai-sdk/openai';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
const result = streamText({
model: openai('@openai-prod/gpt-4o'),
prompt: 'Tell me about the Mission burrito debate in San Francisco.',
});
for await (const chunk of result.fullStream) {
if (chunk.type === 'text-delta') {
process.stdout.write(chunk.textDelta);
}
}
```
### Structured Data Generation
Generate validated, structured outputs with `generateObject`:
```typescript With Schema Name & Description theme={null}
import { generateObject } from 'ai';
import { createOpenAI } from '@ai-sdk/openai';
import { z } from 'zod';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
const result = await generateObject({
model: openai.chat('@openai-prod/gpt-4o'),
schemaName: 'Recipe',
schemaDescription: 'A recipe for a dish.',
schema: z.object({
name: z.string(),
ingredients: z.array(
z.object({
name: z.string(),
amount: z.string(),
})
),
steps: z.array(z.string()),
}),
prompt: 'Generate a lasagna recipe.',
});
console.log(result.object);
```
```typescript Standard Format theme={null}
import { generateObject } from 'ai';
import { createOpenAI } from '@ai-sdk/openai';
import { z } from 'zod';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
const result = await generateObject({
model: openai('@openai-prod/gpt-4o'),
schema: z.object({
recipe: z.object({
name: z.string(),
ingredients: z.array(
z.object({ name: z.string(), amount: z.string() })
),
steps: z.array(z.string()),
}),
}),
prompt: 'Generate a lasagna recipe.',
});
console.log(result.object);
```
### Tool Calling
Enable your AI to use tools and functions:
```typescript theme={null}
import { generateText, tool } from 'ai';
import { createOpenAI } from '@ai-sdk/openai';
import { z } from 'zod';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
const result = await generateText({
model: openai('@openai-prod/gpt-4o'),
tools: {
weather: tool({
description: 'Get the weather in a location',
inputSchema: z.object({
location: z.string().describe('The location to get the weather for'),
}),
execute: async ({ location }) => ({
location,
temperature: 72 + Math.floor(Math.random() * 21) - 10,
}),
}),
},
prompt: 'What is the weather in San Francisco?',
});
console.log(result.text);
console.log('Tool Calls:', result.toolCalls);
```
### Image Generation
Generate images with DALL-E or other image models:
```typescript theme={null}
import { experimental_generateImage as generateImage } from 'ai';
import { createOpenAI } from '@ai-sdk/openai';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
const { image } = await generateImage({
model: openai.image('@openai-prod/dall-e-3'),
prompt: 'Santa Claus driving a Cadillac',
size: '1024x1024',
quality: 'standard',
});
console.log('Image URL:', image);
```
### AI Agents
Build autonomous agents with tool usage and reasoning:
```typescript theme={null}
import { Experimental_Agent as Agent, tool, stepCountIs } from 'ai';
import { createOpenAI } from '@ai-sdk/openai';
import { z } from 'zod';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
const weatherAgent = new Agent({
model: openai('@openai-prod/gpt-4o'),
tools: {
weather: tool({
description: 'Get the weather in a location (in Fahrenheit)',
inputSchema: z.object({
location: z.string().describe('The location to get the weather for'),
}),
execute: async ({ location }) => ({
location,
temperature: 72 + Math.floor(Math.random() * 21) - 10,
}),
}),
convertFahrenheitToCelsius: tool({
description: 'Convert temperature from Fahrenheit to Celsius',
inputSchema: z.object({
temperature: z.number().describe('Temperature in Fahrenheit'),
}),
execute: async ({ temperature }) => ({
celsius: Math.round((temperature - 32) * (5 / 9)),
}),
}),
},
stopWhen: stepCountIs(20),
});
const result = await weatherAgent.generate({
prompt: 'What is the weather in San Francisco in celsius?',
});
console.log('Agent\'s answer:', result.text);
console.log('Steps taken:', result.steps.length);
```
### Custom Parameters
Fine-tune model behavior with temperature, tokens, and retries:
```typescript theme={null}
import { generateText } from 'ai';
import { createOpenAI } from '@ai-sdk/openai';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
const result = await generateText({
model: openai('@openai-prod/gpt-4o'),
maxOutputTokens: 512,
temperature: 0.3,
maxRetries: 5,
prompt: 'Invent a new holiday and describe its traditions.',
});
console.log(result.text);
```
## Portkey Headers
Enhance your requests with Portkey's powerful headers:
### Trace ID
Track and debug requests with custom trace IDs:
```typescript theme={null}
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
headers: {
'x-portkey-trace-id': 'user-123-session-456',
},
});
```
### Metadata
Add custom metadata for filtering and analytics:
```typescript theme={null}
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
headers: {
'x-portkey-metadata': JSON.stringify({
environment: 'production',
user: 'user-123',
feature: 'chat',
}),
},
});
```
### Configs via Headers
Apply Portkey configs using the config ID or inline JSON:
```typescript Config ID theme={null}
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
headers: {
'x-portkey-config': 'pp-config-xxx', // Your config ID
},
});
```
```typescript Inline Config theme={null}
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
headers: {
'x-portkey-config': JSON.stringify({
strategy: { mode: 'fallback' },
targets: [
{ override_params: { model: '@openai-prod/gpt-4o' } },
{ override_params: { model: '@anthropic-prod/claude-3-5-sonnet' } }
]
}),
},
});
```
## Using AI Providers & Model Catalog
Portkey's [Model Catalog](/product/model-catalog) lets you manage all your AI providers and models from a centralized dashboard with governance, budget limits, and access controls.
### Setting Up Providers
1. Go to the [Model Catalog](https://app.portkey.ai) in Portkey dashboard
2. Click "Add Provider" and choose your AI service (OpenAI, Anthropic, etc.)
3. Add your API credentials
4. Give your provider a unique slug (e.g., `@openai-prod`)
### Using Provider Models
Reference models using the `@provider-slug/model-name` format:
```typescript theme={null}
// Use your configured providers
const { text } = await generateText({
model: openai('@openai-prod/gpt-4o'), // OpenAI
prompt: 'Hello!',
});
const { text: claudeText } = await generateText({
model: openai.chat('@anthropic-prod/claude-3-5-sonnet'), // Anthropic
prompt: 'Hello!',
});
const { text: geminiText } = await generateText({
model: openai.chat('@google-prod/gemini-2.0-flash'), // Google
prompt: 'Hello!',
});
```
Centralized management for all your AI providers and models
Set spending controls and rate limits for your providers
## Portkey Configs
Portkey Configs enable advanced routing, reliability, and governance for your AI requests. You can apply configs in two ways:
### Method 1: Inline in Model Name
Reference a saved prompt or config directly in the model name:
```typescript theme={null}
import { generateText } from 'ai';
import { createOpenAI } from '@ai-sdk/openai';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
// Use a saved prompt with config
const { text } = await generateText({
model: openai('@my-prompt-config/gpt-4o'),
prompt: 'User query here',
});
```
### Method 2: Via Headers
Pass config ID or inline config via headers:
```typescript theme={null}
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
headers: {
'x-portkey-config': 'pp-config-xxx', // Your saved config ID
},
});
```
## Enterprise Features
### Observability & Analytics
Get complete visibility into your AI operations with automatic request logging, performance metrics, and cost tracking:
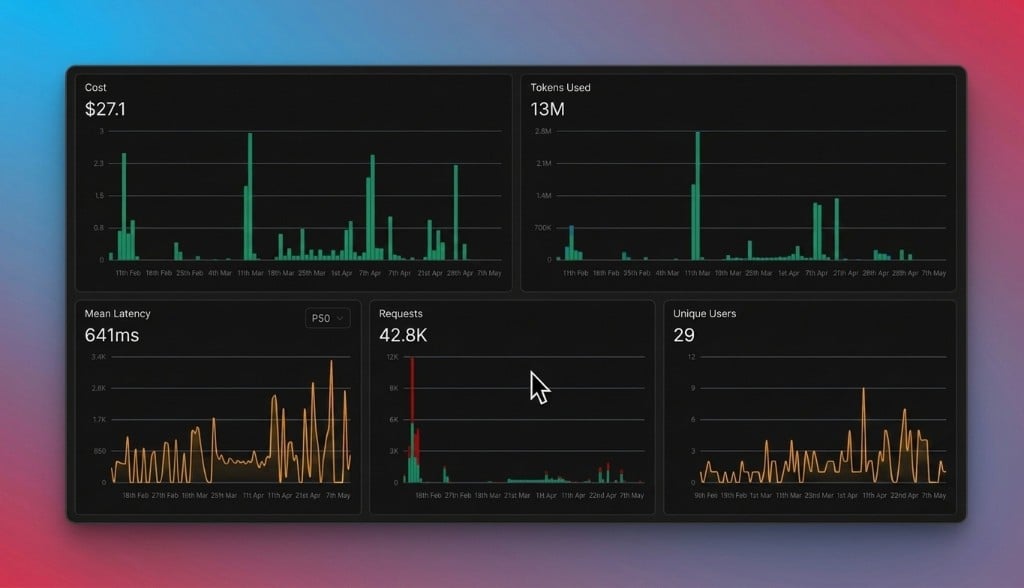 Every request through Portkey is automatically logged with:
* **Request/response payloads** - Full tracing of inputs and outputs
* **Performance metrics** - Latency, tokens, and throughput
* **Cost tracking** - Real-time spend across all providers
* **Error monitoring** - Automatic error detection and alerts
Explore Portkey's full observability suite
### AI Gateway Features
Portkey's AI Gateway makes your AI applications production-ready with enterprise reliability:
Automatic failover between models and providers
Distribute traffic across multiple providers
Smart retry logic for transient failures
Reduce costs by 80% with semantic caching
Handle unresponsive requests gracefully
Route requests based on custom logic
View all gateway features and capabilities
### Guardrails
Enforce safety, quality, and compliance with real-time guardrails:
```json theme={null}
{
"before_request_hooks": [{
"id": "input-guardrail-xxx"
}],
"after_request_hooks": [{
"id": "output-guardrail-xxx"
}]
}
```
Portkey offers 50+ built-in guardrails including:
* PII detection and redaction
* Toxic content filtering
* Prompt injection protection
* Custom regex and keyword filters
* Sensitive data detection
Set up real-time safety and compliance checks
### Prompt Management
Manage, version, and deploy prompts from Portkey's Prompt Studio:
Test prompts across 250+ models side-by-side
Version control for all your prompts
Centralized prompt repository
Deploy prompts via API endpoints
## Migration Guide
### From `@portkey-ai/vercel-provider`
If you're migrating from the old Portkey Vercel provider package:
**Before:**
```typescript theme={null}
import { createPortkey } from '@portkey-ai/vercel-provider';
const portkey = createPortkey({
apiKey: 'YOUR_PORTKEY_API_KEY',
config: { /* ... */ }
});
const { text } = await generateText({
model: portkey.chatModel('gpt-4o'),
prompt: 'Hello',
});
```
**After:**
```typescript theme={null}
import { createOpenAI } from '@ai-sdk/openai';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
const { text } = await generateText({
model: openai('@openai-prod/gpt-4o'),
prompt: 'Hello',
});
```
**Key Changes:**
* Use `@ai-sdk/openai` instead of `@portkey-ai/vercel-provider`
* Set `baseURL` to Portkey's gateway
* Reference models using `@provider-slug/model-name` format
* Pass configs via headers or inline in model names
**Benefits:**
* ✅ Better compatibility with Vercel AI SDK updates
* ✅ Access to all Vercel AI SDK features immediately
* ✅ Simpler setup with standard OpenAI provider
* ✅ More flexible config management
## Support & Resources
Complete API documentation
Get help from the community
Reach out to our team
Contribute to Portkey Gateway
Every request through Portkey is automatically logged with:
* **Request/response payloads** - Full tracing of inputs and outputs
* **Performance metrics** - Latency, tokens, and throughput
* **Cost tracking** - Real-time spend across all providers
* **Error monitoring** - Automatic error detection and alerts
Explore Portkey's full observability suite
### AI Gateway Features
Portkey's AI Gateway makes your AI applications production-ready with enterprise reliability:
Automatic failover between models and providers
Distribute traffic across multiple providers
Smart retry logic for transient failures
Reduce costs by 80% with semantic caching
Handle unresponsive requests gracefully
Route requests based on custom logic
View all gateway features and capabilities
### Guardrails
Enforce safety, quality, and compliance with real-time guardrails:
```json theme={null}
{
"before_request_hooks": [{
"id": "input-guardrail-xxx"
}],
"after_request_hooks": [{
"id": "output-guardrail-xxx"
}]
}
```
Portkey offers 50+ built-in guardrails including:
* PII detection and redaction
* Toxic content filtering
* Prompt injection protection
* Custom regex and keyword filters
* Sensitive data detection
Set up real-time safety and compliance checks
### Prompt Management
Manage, version, and deploy prompts from Portkey's Prompt Studio:
Test prompts across 250+ models side-by-side
Version control for all your prompts
Centralized prompt repository
Deploy prompts via API endpoints
## Migration Guide
### From `@portkey-ai/vercel-provider`
If you're migrating from the old Portkey Vercel provider package:
**Before:**
```typescript theme={null}
import { createPortkey } from '@portkey-ai/vercel-provider';
const portkey = createPortkey({
apiKey: 'YOUR_PORTKEY_API_KEY',
config: { /* ... */ }
});
const { text } = await generateText({
model: portkey.chatModel('gpt-4o'),
prompt: 'Hello',
});
```
**After:**
```typescript theme={null}
import { createOpenAI } from '@ai-sdk/openai';
const openai = createOpenAI({
baseURL: 'https://api.portkey.ai/v1',
apiKey: 'YOUR_PORTKEY_API_KEY',
});
const { text } = await generateText({
model: openai('@openai-prod/gpt-4o'),
prompt: 'Hello',
});
```
**Key Changes:**
* Use `@ai-sdk/openai` instead of `@portkey-ai/vercel-provider`
* Set `baseURL` to Portkey's gateway
* Reference models using `@provider-slug/model-name` format
* Pass configs via headers or inline in model names
**Benefits:**
* ✅ Better compatibility with Vercel AI SDK updates
* ✅ Access to all Vercel AI SDK features immediately
* ✅ Simpler setup with standard OpenAI provider
* ✅ More flexible config management
## Support & Resources
Complete API documentation
Get help from the community
Reach out to our team
Contribute to Portkey Gateway